この記事を書いた人
DROBE の都筑 (@tsuzukit2) です
簡単なプロフィールはこちらをご覧ください
はじめに
機械学習系の機能を開発していると、GPU を利用してトレーニングを行いたいケースが多々あると思います。
この記事では、ECS で GPU を使った ML 系 Task の実行環境のセットアップについて記載します。
作りたいもの
作りたいものの概要はこのようなものです。
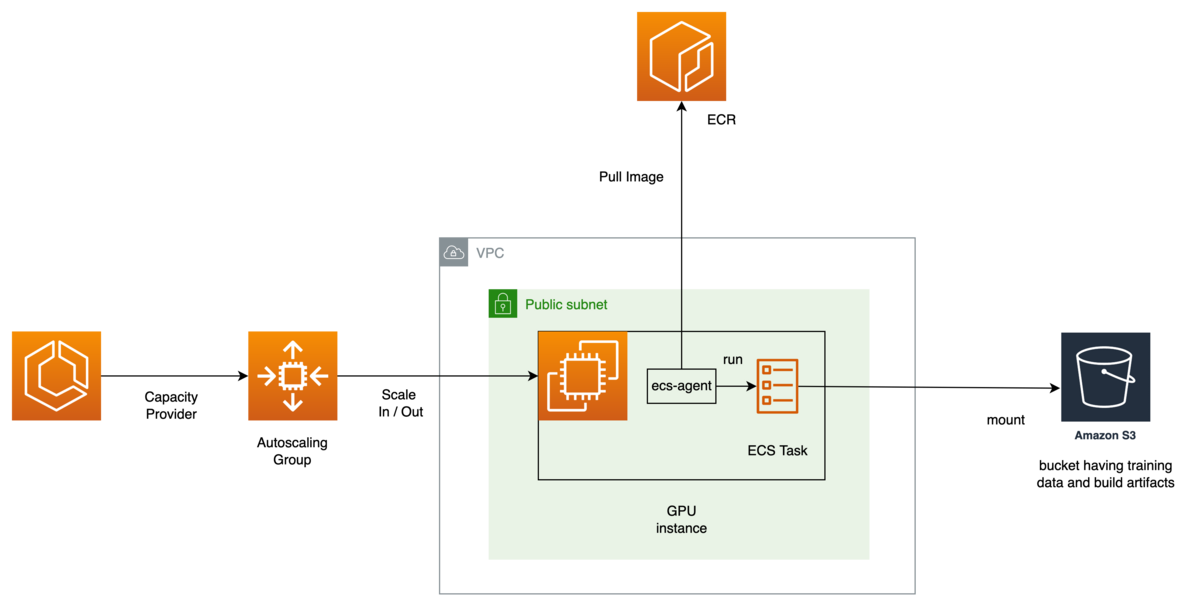
GPU は高価なので、常時起動しているインスタンスは 0 としておきつつ、Task が作られたらインスタンスを起動、Task を実行、Task の実行が終わったらインスタンスを落とし 0 に戻す、という環境をセットアップします。
ECS の capacity provider と autoscaling group を紐付け、ECS Task が起動 / 終了のタイミングで必要なインスタンスが変更される構成です。
ECS Task は goofys を利用して S3 をマウントする事とします。S3 をマウントするのは、画像系機械学習モデルのトレーニングに大量の画像が必要であり、それを S3 にマウントする事でコードで S3 の API などを意識せずに使えるようにするためです。
goofys については、こちらの repo を参考にしてください。
ECS で実行するタスクの定義と実行
ECS で実行するタスク定義は事前に Terraform で作っておく事としました。Task 定義の中で実際に training を行うコンテナは latest tag のものを実行するように指定しておきます。 Task を実行する際には、GitHub Actions にてコンテナをビルドし ECR に push (ここで latest tag のイメージが更新されます) し、AWS CLI を使って Task を起動するという流れです。
GitHub Actions は以下のようなものになります。
name: invoke ml training on: workflow_dispatch: jobs: build: name: build container image runs-on: ubuntu-latest steps: - name: source checkout uses: actions/checkout@v3 - name: Configure AWS credentials uses: aws-actions/configure-aws-credentials@v2 with: aws-access-key-id: ${{ AWS_ACCESS_KEY_ID }} aws-secret-access-key: ${{ AWS_SECRET_ACCESS_KEY }} aws-region: ap-northeast-1 - name: Login to Amazon ECR id: login-ecr uses: aws-actions/amazon-ecr-login@v1 - name: Build and push to ecr run: | make build # 自作のコンテナを build するためのコマンド docker tag trainer:latest xxxx.dkr.ecr.ap-northeast-1.amazonaws.com/trainer:latest docker push xxxx.dkr.ecr.ap-northeast-1.amazonaws.com/trainer:latest:latest docker tag trainer:latest xxxx.dkr.ecr.ap-northeast-1.amazonaws.com/trainer:${GITHUB_SHA} docker push xxxx.dkr.ecr.ap-northeast-1.amazonaws.com/trainer:${GITHUB_SHA} run: name: run ecs task runs-on: ubuntu-latest needs: [build] steps: - name: Configure AWS credentials uses: aws-actions/configure-aws-credentials@v2 with: aws-access-key-id: ${{ secrets.AWS_ACCESS_KEY_ID }} aws-secret-access-key: ${{ secrets.AWS_SECRET_ACCESS_KEY }} aws-region: ap-northeast-1 - name: run-task env: CLUSTER_NAME: ml-train # terraform で定義した cluster 名に合わせる FAMILY_NAME: trainer # terraform で定義した task 定義に合わせる run: | TASK_DEF_ARN=$(aws ecs list-task-definitions --family-prefix "${FAMILY_NAME}" --query "reverse(taskDefinitionArns)[0]" --output text) echo "${TASK_DEF_ARN}" TASK_ARN=$(aws ecs run-task --cluster ${CLUSTER_NAME} --task-definition ${TASK_DEF_ARN} --query tasks[0].taskArn --output text) TASK_ID=$(echo "${TASK_ARN}" | grep -oE "[^/]+$")
Terraform
全体の構成が決まったので Terraform の設定を書いていきます。 (注 公開するために命名などを修正しており動作未検証なのでコピペでの使用は避けてください)
まずは VPC などネットワーク周りの設定を書きます。
# VPC resource "aws_vpc" "vpc_name" { cidr_block = "10.0.0.0/16" enable_dns_hostnames = true enable_dns_support = true tags = { Name = "vpc_name" } } # Public subnet resource "aws_subnet" "subnet" { vpc_id = aws_vpc.vpc_name.id availability_zone = "ap-northeast-1a" cidr_block = "10.0.1.0/24" map_public_ip_on_launch = true } resource "aws_internet_gateway" "ig" { vpc_id = aws_vpc.vpc_name.id } resource "aws_route_table" "rt" { vpc_id = aws_vpc.vpc_name.id } resource "aws_route" "route" { route_table_id = aws_route_table.rt.id destination_cidr_block = "0.0.0.0/0" gateway_id = aws_internet_gateway.ig.id } resource "aws_route_table_association" "rta" { subnet_id = aws_subnet.subnet.id route_table_id = aws_route_table.rt.id } resource "aws_security_group" "sg" { name = "sg" vpc_id = aws_vpc.vpc_name.id depends_on = [ aws_vpc.vpc_name ] ingress { from_port = "0" to_port = "0" protocol = "-1" cidr_blocks = ["0.0.0.0/0"] } egress { from_port = "0" to_port = "0" protocol = "-1" cidr_blocks = ["0.0.0.0/0"] } }
次に ECR などを書いていきます
# ECR resource "aws_ecr_repository" "ecr_repo" { name = "trainer" } # ECR Lifecycle policy resource "aws_ecr_lifecycle_policy" "lsp" { repository = each.value.ecr_repo policy = <<EOF { "rules": [ { "rulePriority": 1, "description": "Keep last 2 images", "selection": { "tagStatus": "tagged", "tagPrefixList": ["v"], "countType": "imageCountMoreThan", "countNumber": 2 }, "action": { "type": "expire" } } ] } EOF }
続いて Task 定義を作ります
ここで goofys や GPU を使うための設定を行います
# Task 定義 resource "aws_ecs_task_definition" "task" { family = "trainer" requires_compatibilities = ["EC2"] network_mode = "bridge" cpu = 2048 memory = 8192 task_role_arn = aws_iam_role.iam.arn execution_role_arn = aws_iam_role.iam.arn container_definitions = jsonencode([ { image = "xxxx.dkr.ecr.ap-northeast-1.amazonaws.com/${aws_ecr_repository.ecr_repo.name}:latest" # ここで latest を指定する essential = true, name = "trainer" cpu = 2048, memory = 8192, logConfiguration = { logDriver = "awslogs", options = { awslogs-group = aws_cloudwatch_log_group.ml_image_recognition_train.name, awslogs-region = "ap-northeast-1", awslogs-stream-prefix = "ml_image_recognition" } }, linuxParameters = { # goofys を使うための設定 capabilities = { add = [ "MKNOD", "SYS_ADMIN" ] }, "devices" : [ { "hostPath" : "/dev/fuse", "containerPath" : "/dev/fuse", "permissions" : [ "read", "write", "mknod" ] } ] }, environment = [ { name = "NVIDIA_DRIVER_CAPABILITIES", value = "all" } ], resourceRequirements = [ # GPU を使うための設定 { type = "GPU", value = "1" } ] } ]) } resource "aws_iam_role" "iam" { name = "ecs-iam" assume_role_policy = <<EOF { "Version": "2012-10-17", "Statement": [ { "Action": "sts:AssumeRole", "Principal": { "Service": "ecs-tasks.amazonaws.com" }, "Effect": "Allow" } ] } EOF } resource "aws_iam_role_policy" "iam_policy" { role = aws_iam_role.iam.id policy = <<EOF { "Version": "2012-10-17", "Statement": [ { "Action": [ "logs:CreateLogGroup", "logs:CreateLogStream", "logs:PutLogEvents", "logs:DescribeLogGroups", "logs:DescribeLogStreams" ], "Effect": "Allow", "Resource": "${aws_cloudwatch_log_group.lg.arn}" }, { "Action": [ "s3:ListBucket", "s3:GetObject", "s3:PutObject" ], "Effect": "Allow", "Resource": [ "*" # goofys でマウントしたいバケットを指定する ] } ] } EOF } resource "aws_cloudwatch_log_group" "trainer" { name = "/ecs/logs/prod/trainer" retention_in_days = 14 }
最後に cluster の定義や Autoscaling Group の設定を書いていきます。aws_laumch_template で使いたいインスタンスタイプを指定します。ここでは g4dn.xlarge を指定しています。
# ecs cluster resource "aws_ecs_cluster" "cluster" { name = "ml-train" } resource "aws_ecs_cluster_capacity_providers" "trainer" { cluster_name = aws_ecs_cluster.cluster.name capacity_providers = [aws_ecs_capacity_provider.trainer.name] default_capacity_provider_strategy { base = 0 weight = 1 capacity_provider = aws_ecs_capacity_provider.trainer.name } } resource "aws_ecs_capacity_provider" "trainer" { name = "trainer" auto_scaling_group_provider { auto_scaling_group_arn = aws_autoscaling_group.trainer.arn managed_termination_protection = "ENABLED" managed_scaling { maximum_scaling_step_size = 10 minimum_scaling_step_size = 1 status = "ENABLED" target_capacity = 100 } } } resource "aws_autoscaling_group" "trainer" { name = "trainer" max_size = 1 min_size = 0 health_check_grace_period = 0 health_check_type = "EC2" desired_capacity = 0 vpc_zone_identifier = [aws_subnet.trainer.id] launch_template { id = aws_launch_template.trainer.id version = "$Latest" } tag { # ECSにスケーリングをお願いするために必要なタグ # https://docs.aws.amazon.com/ja_jp/AmazonECS/latest/developerguide/cluster-auto-scaling.html#update-ecs-resources-cas key = "AmazonECSManaged" value = "" propagate_at_launch = true } lifecycle { ignore_changes = [ desired_capacity, ] } } locals { node_group_user_data = <<-EOF #!/bin/bash set -o xtrace echo ECS_CLUSTER=${aws_ecs_cluster.ml_image_recognition_train.name} >> /etc/ecs/ecs.config; EOF } resource "aws_launch_template" "trainer" { name = "trainer" # https://docs.aws.amazon.com/ja_jp/AmazonECS/latest/developerguide/retrieve-ecs-optimized_AMI.html image_id = "ami-087da40e7559e6193" instance_type = "g4dn.xlarge" key_name = "xxxxx" vpc_security_group_ids = [aws_security_group.trainer.id] block_device_mappings { device_name = "/dev/xvda" ebs { volume_size = 200 } } instance_market_options { market_type = "spot" # spot の方が金額は安いが長時間の学習では spot だと止まってしまう事があった } iam_instance_profile { arn = aws_iam_instance_profile.trainer.arn } user_data = base64encode(format(local.node_group_user_data)) } data "aws_iam_policy" "AmazonEC2ContainerServiceforEC2Role" { arn = "arn:aws:iam::aws:policy/service-role/AmazonEC2ContainerServiceforEC2Role" } resource "aws_iam_role_policy_attachment" "trainer" { for_each = toset([ "arn:aws:iam::aws:policy/service-role/AmazonECSTaskExecutionRolePolicy", "arn:aws:iam::aws:policy/AmazonEC2ContainerRegistryReadOnly", ]) role = aws_iam_role.trainer.name policy_arn = each.value } data "aws_iam_policy" "AmazonEC2ContainerServiceforEC2Role" { arn = "arn:aws:iam::aws:policy/service-role/AmazonEC2ContainerServiceforEC2Role" } resource "aws_iam_role" "trainer" { name = "trainer" assume_role_policy = <<EOF { "Version": "2012-10-17", "Statement": [ { "Action": "sts:AssumeRole", "Principal": { "Service": "ec2.amazonaws.com" }, "Effect": "Allow", "Sid": "" } ] } EOF } resource "aws_iam_role_policy_attachment" "trainer" { policy_arn = data.aws_iam_policy.AmazonEC2ContainerServiceforEC2Role.arn role = aws_iam_role.trainer.name } resource "aws_iam_instance_profile" "trainer" { role = aws_iam_role.trainer.name }
CapacityProviderReservation について
ECS のインスタンス数を増減させる仕組みとして CapacityProvider を使います。それらの説明は公式のブログに詳しいので一読ください。
Amazon ECS クラスターの Auto Scaling を深く探る | Amazon Web Services
CapacityProvider を利用した Autoscaling においては、クラスターが必要とするインスタンス数と実際に稼働しているインスタンスの数を比率で表した CapacityProviderReservation という値をあらかじめ設定しておき、その値になるようにインスタンス数を ASG が自動で調節します。若干解り伝いのですが、公式の説明を読むとイメージが掴めます。
CAS の中心的な責任は、ASG に割り当てられたタスクの必要を満たす上で「適切な」数のインスタンスが ASG で実行されるようにすることです。これには、既に実行されているタスクと、既存のインスタンスには収まらない、顧客が実行しようとしているタスクの両方が含まれます。その数を M としましょう。また、既に実行されている ASG 内の現在のインスタンス数を N とします。この記事の残りの部分では M と N が繰り返し出てくるので、これらをどう考えたらよいかを十分明確に理解しておくことが重要です。 今のところ、M をいくらにしたらよいかを知る方法は説明していませんが、議論の目的上、M は必要数であるとだけ仮定します。この仮定の下で、もし N = M であるとするなら、スケールアウトは必要ではなく、スケールインは不可能です。一方、N < M なら、十分なインスタンスがないことになるので、スケールアウトが必要です。 最後に N > M なら、スケールインが可能です (ただし必要だとは限りません)。自分の ECS タスクすべてを実行するのに必要な数よりも多くのインスタンスが存在しているからです。また、後ほど見るように、N と M に基づく新しい CloudWatch メトリクスを定義し、それを
CapacityProviderReservationと呼ぶことにします。N と M が与えられたときのこのメトリクスの定義は非常にシンプルです。
簡単に説明するなら、このメトリクスは、ASG の実際の大きさと必要な大きさとの比を、パーセント単位で表したものです。

terraform ではこの CapacityProviderReservation を設定する形になります
resource "aws_ecs_capacity_provider" "trainer" { name = "trainer" auto_scaling_group_provider { auto_scaling_group_arn = aws_autoscaling_group.trainer.arn managed_termination_protection = "ENABLED" managed_scaling { maximum_scaling_step_size = 10 minimum_scaling_step_size = 1 status = "ENABLED" target_capacity = 100 # <- ここ } } }
ここで 100 を指定するという事は、「タスクを実行するのにちょうど必要な数のインスタンスを準備してください」ということになります。
例えばここで 200 を指定しておくと、「タスクを実行するのに必要なインスタンスの数の 2 倍のインスタンスを準備してください」ということです。
CapacityProviderReservation を 100 にしておくことで、タスクのリクエストが無い時はインスタンスの数が 0 になるように出来ます。(GPU インスタンスは非常に高いので使っていない時に 0 に出来るという事はメリットが大きいはずです)
Trouble Shooting
ここからは、環境を構築するにあたって実際にハマってしまったポイントを 2 つ紹介します。
インスタンスが起動はするが ECS に参加しない
ECS クラスターが作られ EC2 インスタンスも建っているのに、training が始まらない場合は EC2 が ECS クラスターに参加できているかを確認してみてください。
EC2 インスタンスを ECS クラスターに参加させるためには、EC2 の /etc/ecs/ecs.config に ECS_CLUSTER 環境変数をセットする必要がありました。
terraform では以下の辺りになります。
locals { node_group_user_data = <<-EOF #!/bin/bash set -o xtrace echo ECS_CLUSTER=${aws_ecs_cluster.trainer.name} >> /etc/ecs/ecs.config; EOF } resource "aws_launch_template" "trainer" { name = "trainer" ...省略 user_data = base64encode(format(local.node_group_user_data)) }
Training が 20 時間程度で終わってしまう
環境を構築してから何回か training を実行しましたが、どうしても 20 時間程度で勝手に training が終了してしまうという現象に遭遇しました。
最初はメモリーなどを疑いましたが試しに無限に sleep をし続ける training task を作って実行しても同様の結果になってしまいました。
調査した結果、どうやらスポットインスタンスを使っている事が原因だったようです。
スポットインスタンスの設定を削除した結果数日に及ぶようなトレーニングでも実行を行える事が確認できました。
terraform ではこの辺りになります。
resource "aws_launch_template" "trainer" { ... 省略 instance_market_options { market_type = "spot" # spot の方が金額は安いが長時間の学習では spot だと止まってしまう事があった } }
おわりに
ML をやっていると GPU を使いたくなる事は多々あり、かつ本番環境への Deploy などを考えると自動のパイプラインとして GPU によるトレーニングを組みたくなる事は多いと思います。
一方で GPU インスタンスは非常に高価であるため、使っていない時は落としておきたいと思うのが人情だと思います。
この記事では ECS で GPU を使った ML 系 Task の実行環境のセットアップについて解説しました。特に必要のない時にはインスタンス数を 0 にしておける設定なので、特にコストにシビアなスタートアップの方などに少しでも参考になれば嬉しいです。